Difference between revisions of "Super Computing 2016"
(→Miscellaneous Thoughts and Remarks) |
(→Miscellaneous Thoughts and Remarks) |
||
| Line 62: | Line 62: | ||
* nvidia is now 28th on the list of [https://www.top500.org/news/nvidia-keeps-ai-front-and-center-at-sc16/ top 500 supercomputers] | * nvidia is now 28th on the list of [https://www.top500.org/news/nvidia-keeps-ai-front-and-center-at-sc16/ top 500 supercomputers] | ||
* I also attended an invited talk by '''Maria Klawe''', president of Harvey Mudd College. Always a champion of diversity and inclusion. HPC is a bit behind, seems like, and people like Klawe can make a big impact. Good! | * I also attended an invited talk by '''Maria Klawe''', president of Harvey Mudd College. Always a champion of diversity and inclusion. HPC is a bit behind, seems like, and people like Klawe can make a big impact. Good! | ||
| − | * [[Image:MooresLaw10MoreYears.jpg|right| | + | * [[Image:MooresLaw10MoreYears.jpg|right|350px]] '''Thomas Theis''':<br /><blockquote>''' "We still have 10 more years or so of Moore's Law" ''' |
</blockquote><br /> | </blockquote><br /> | ||
:Theis gave a talk titled "Beyond Exascale: Emerging Devices and Architectures for Computing," and presented a graph very similar to the one on the right (which I took from [https://www.nextplatform.com/2015/08/04/future-systems-pitting-fewer-fat-nodes-against-many-skinny-ones/ this site]), and which I saw appear in several talks this week. He really was talking about Moore's Law for transistors, but obviously the power, clock speed, and number of cores hasn't followed the exponential growth we've seen with transistors. Below is an interesting quote from the page announcing [http://sc16.supercomputing.org/2016/09/22/sc16-invited-talk-spotlight-dr-thomas-n-theis-presents-beyond-exascale-emerging-devices-architectures-computing/ Theis's talk]: | :Theis gave a talk titled "Beyond Exascale: Emerging Devices and Architectures for Computing," and presented a graph very similar to the one on the right (which I took from [https://www.nextplatform.com/2015/08/04/future-systems-pitting-fewer-fat-nodes-against-many-skinny-ones/ this site]), and which I saw appear in several talks this week. He really was talking about Moore's Law for transistors, but obviously the power, clock speed, and number of cores hasn't followed the exponential growth we've seen with transistors. Below is an interesting quote from the page announcing [http://sc16.supercomputing.org/2016/09/22/sc16-invited-talk-spotlight-dr-thomas-n-theis-presents-beyond-exascale-emerging-devices-architectures-computing/ Theis's talk]: | ||
Revision as of 17:25, 17 November 2016
--D. Thiebaut (talk) 10:39, 14 November 2016 (EST)
I attended the SuperComputer 2016 (SC16) conference in Salt Lake City, UT, in Nov. 2016. The conference deals with all issues relating to supercomputing, high performance computing (HPC), and any domain where massive orders or computation are required.
|
|
|
|
|
|




Contents
Parallel Processing Tutorial
I attended a 1-day tutorial on parallel processing. I knew 95% of the material, but this actually was a great way of reviewing the material I will teach in my parallel and distributed processing class CSC352 in the spring of 2017, and see what I needed to drop or add to the course. The tutorial was presented by Quentin F. Stout and Christiane Jablonowski of U. Michigan. I was happy to see that my current syllabus is quite up to speed with what is important to the field, and I just need to revise it by adding a new section on GPUs and accelerators. GPUs will likely become one of the biggest players in parallel computing in the next few years from their use in machine learning and deep learning in particular, and running neural network operations. NVidia seems to be the company at the head of the game, with Intel's Xeon Phi a competitor in HPC and machine learning. C and C++ are still the languages of choice, and I will keep my module on teaching C & C++ (maybe not C++ classes) in the seminar.
In case you'd like to know the contents of the tutorial, here it is in its entirety, as a word cloud... :-)

EduHPC 16
There was also an afternoon session relating to education of HPC in undergraduate schools, and I was on the technical committee for this session (Monday 11/14/16).
Miscellaneous Thoughts and Remarks
I attended several talks, plenary and research, and am listing some of the main ideas here, mostly to help myself remember them. There is no special order or categorization.
- There's a lot of hardware on the exhibitors floor! When I went to the Amazon AWS conference in New York City, the exhibitors were mostly service companies offering software applications that operated on top of AWS. Here, many companies provide hardware platforms on top of GPUs to support all kind of HPC apps, including machine learning.

- Teaching HPC is important for students interested in Machine Learning (ML).
- GPUs are here to stay. They are power hungry, but they are perfectly suited for matrix operations, which is what neural nets are all about. Not surprising that Google is manufacturing its own GPU boards/servers (Tensor Processing Units--TPU) to support its machine learning research. Found out about TPUs last may, when I attended Google IO 2016.
- For the first time this year, SC16 included panels and workshop dedicated to the retention of minorities in HPC, and to K-12, 8-12 education. The current percentage of women in HPC is around 20%. Our CS department at Smith is now in its third year of a grant from the AAC&U (PKal/TIDES grant) to enhance the retention of underrepresented students in computer science).
- I attended a talk "Simulation and Performance Analysis of the ECMWF Tape Library System," by Markus Mäsker et al, from the Johannes Gutenberg University of Mainz, Germany, on the performance of a tape library where a robot feeds tapes to a finite collection of drives (12). Using traces of the accesses the robots make to tapes, the authors evaluated various policies for speeding up the access to tape, hence reducing the long latency in accessing files. More than 20 years ago I was doing the same kind of research, but the traces were traces of processors accessing memory, and the algorithms I was looking at were to best bring information into cache memory. It seems that as technology progresses, lessons learned can be applied to new levels of memory hierarchy. In particular, I'm wondering if some machine learning couldn't help reduce the latency by analyzing passed requests, and predicting future ones, in an effort to bring a tape in a drive before it is actually requested. (This paper looks like good background information).
- Quote taken from the plenary talk by Katharine Frase, of IBM:

“The business plans of the next 10,000 startups are easy to forecast: take X and add AI”
— Kevin Kelly, Wired Magazine.
- See this article for insights.
- Another interesting talk, "Real-Time Synthesis of Compression Algorithms for Scientific Data," authored by Martin Burtscher, Hari Mukka, Annie Yang, and Farbod Hesaaraki. The paper presents a new way of compressing data that is based on various simple techniques for filtering data, and simplified machine learning for figuring out how to pipeline these basic filters to best compress the data at hand. The compression method stores the meta-data about the pipeline used to compress the data in the compressed file. The method sports a better compression ratio than gzip, and bzip2, and faster decompression time than these algorithms. The compression time, though, is slightly longer because of the machine learning. This is another example of X + AI. Interesting!
- nvidia is now 28th on the list of top 500 supercomputers
- I also attended an invited talk by Maria Klawe, president of Harvey Mudd College. Always a champion of diversity and inclusion. HPC is a bit behind, seems like, and people like Klawe can make a big impact. Good!
- Thomas Theis:
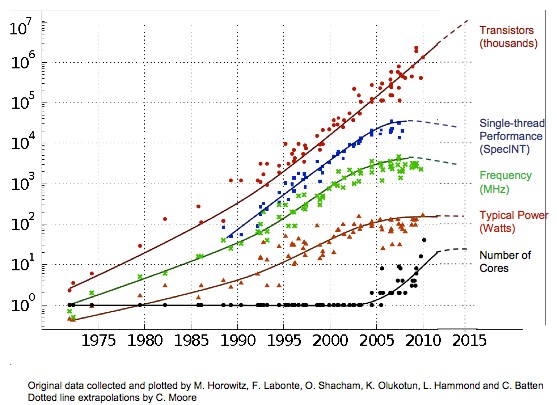
"We still have 10 more years or so of Moore's Law"

- Theis gave a talk titled "Beyond Exascale: Emerging Devices and Architectures for Computing," and presented a graph very similar to the one on the right (which I took from this site), and which I saw appear in several talks this week. He really was talking about Moore's Law for transistors, but obviously the power, clock speed, and number of cores hasn't followed the exponential growth we've seen with transistors. Below is an interesting quote from the page announcing Theis's talk:
The continuing evolution of silicon complementary metal–oxide–semiconductor (CMOS) technology is clearly approaching some important physical limits. Since roughly 2003, the inability to reduce supply voltages according to constant-electric-field scaling rules, combined with economic constraints on power density and total power, has forced designers to limit clock frequencies even as devices have continued to shrink. Still, there is a plausible path to Exascale, based on the continued evolution of silicon device technology, silicon photonics, 3D integration, and more.
- Something funny. Couldn't find the author of this great little gif... It looks like many solutions people are using to boost the performance of HPC applications...

Super Moon
An important detail: my week in Salt Lake City coincided with the super moon (super moon for super computing conference--that makes sense!), the biggest and brightest supermoon to rise in almost 69 years. So I had to document this! You can see some more of it on my instagram feed.
