Difference between revisions of "CSC352 Resources"
(→Literature) |
|||
| (12 intermediate revisions by the same user not shown) | |||
| Line 66: | Line 66: | ||
==Documentation on Python Threads== | ==Documentation on Python Threads== | ||
| − | + | ||
[[Image:smilingPython.png| right| 100px]] | [[Image:smilingPython.png| right| 100px]] | ||
* [http://python.org/ The main Python reference] | * [http://python.org/ The main Python reference] | ||
| Line 74: | Line 74: | ||
* [http://www.slideshare.net/pvergain/multiprocessing-with-python-presentation Multiprocessing with Python] a presentation by Jesse Noller who wrote the PEP 371 | * [http://www.slideshare.net/pvergain/multiprocessing-with-python-presentation Multiprocessing with Python] a presentation by Jesse Noller who wrote the PEP 371 | ||
* [http://blip.tv/file/2232410 Video Presentation] on the Python GIL (found by Diana) | * [http://blip.tv/file/2232410 Video Presentation] on the Python GIL (found by Diana) | ||
| − | |||
==Documentation on XGrid== | ==Documentation on XGrid== | ||
| − | + | ||
[[Image:xgridLogo.png | right|100px]] | [[Image:xgridLogo.png | right|100px]] | ||
| Line 106: | Line 105: | ||
* [http://www.macos.utah.edu/documentation/administration/xgrid/xgrid_presentation.html Utah] Xgrid: Lots of good stuff. | * [http://www.macos.utah.edu/documentation/administration/xgrid/xgrid_presentation.html Utah] Xgrid: Lots of good stuff. | ||
* [http://reference.wolfram.com/mathematica/guide/StandaloneMathematicaKernels.html Using the Mathematica Kernel]. | * [http://reference.wolfram.com/mathematica/guide/StandaloneMathematicaKernels.html Using the Mathematica Kernel]. | ||
| − | |||
| − | |||
==Documentation on Cloud Computing, Map-Reduce, & Hadoop== | ==Documentation on Cloud Computing, Map-Reduce, & Hadoop== | ||
| Line 113: | Line 110: | ||
Ken Arnold, CORBA Designer | Ken Arnold, CORBA Designer | ||
</blockquote> | </blockquote> | ||
| − | |||
__NOTOC__ | __NOTOC__ | ||
===Literature=== | ===Literature=== | ||
| − | * [[Image:hadoopOReilly.jpg | right |100px]] [http://www.amazon.com/Hadoop-Definitive-Guide-Tom-White/dp/0596521979 Hadoop, the definitive guide], | + | * [[Media:ApacheChapterOnStreaming.pdf | Apache's chapter on Hadoop Streaming]], Apache.org. |
| + | * [http://answers.oreilly.com/topic/460-how-to-benchmark-a-hadoop-cluster/ How to Benchmark a Hadoop Cluster], by Tom White, [http://answers.oreilly.com O'Reilly Answers], Oct. 2009. | ||
| + | * [[Image:hadoopOReilly.jpg | right |100px]] [http://www.amazon.com/Hadoop-Definitive-Guide-Tom-White/dp/0596521979 Hadoop, the definitive guide], Tom White, O'Reilly Media, June 2009, ISBN 0596521979. The Web site for the book is http://www.hadoopbook.com/ (with the data used as examples in the book) | ||
* Dan Sullivan [http://nexus.realtimepublishers.com/dgcc.php The Definitive Guide to Cloud Computing], IBM, 2010, ''in production'' (but can be downloaded in parts). | * Dan Sullivan [http://nexus.realtimepublishers.com/dgcc.php The Definitive Guide to Cloud Computing], IBM, 2010, ''in production'' (but can be downloaded in parts). | ||
* Dean, J., and S. Ghemawat, [http://labs.google.com/papers/mapreduce-osdi04.pdf MapReduce: Simplified Data Processing on Large Clusters], Dec. 2004, ([[media:MapReduce1204.pdf|cached copy]]) | * Dean, J., and S. Ghemawat, [http://labs.google.com/papers/mapreduce-osdi04.pdf MapReduce: Simplified Data Processing on Large Clusters], Dec. 2004, ([[media:MapReduce1204.pdf|cached copy]]) | ||
| Line 132: | Line 130: | ||
* Matthews, S., & Williams, T. [http://www.biomedcentral.com/1471-2105/11/S1/S15 MrsRF: an efficient MapReduce algorithm for analyzing large collections of evolutionary trees BMC Bioinformatics], 11, 2010 (Suppl 1) <font color=magenta>(authors show that speedups of close to 18 on 32 cores can be reached for treating 20,000 trees of 150 taxa each and 33,306 trees of 567 taxa each.)</font> | * Matthews, S., & Williams, T. [http://www.biomedcentral.com/1471-2105/11/S1/S15 MrsRF: an efficient MapReduce algorithm for analyzing large collections of evolutionary trees BMC Bioinformatics], 11, 2010 (Suppl 1) <font color=magenta>(authors show that speedups of close to 18 on 32 cores can be reached for treating 20,000 trees of 150 taxa each and 33,306 trees of 567 taxa each.)</font> | ||
* Chris K Wensel, [http://www.manamplified.org/archives/2008/11/hadoop-is-about-scalability.html Hadoop Is About Scalability, Not Performance], www.manamplified.org, November 12, 2008. | * Chris K Wensel, [http://www.manamplified.org/archives/2008/11/hadoop-is-about-scalability.html Hadoop Is About Scalability, Not Performance], www.manamplified.org, November 12, 2008. | ||
| − | * Paulson, Rasin, Abadi, DeWitt, Madden, and Stonebraker, [[Media:ComparisonOfApproachesToLargeScaleDataAnalysis.pdf |A Comparison of Approaches to Large Scale Data-Analysis]], SIGMOD-09, June 2009. | + | * Pavlo, Paulson, Rasin, Abadi, DeWitt, Madden, and Stonebraker, [[Media:ComparisonOfApproachesToLargeScaleDataAnalysis.pdf |A Comparison of Approaches to Large Scale Data-Analysis]], SIGMOD-09, June 2009. |
* [[Image:mapReduceTaskTimeLine.png|right|150px]]<u>TimeLine Graphs and Performance</u> | * [[Image:mapReduceTaskTimeLine.png|right|150px]]<u>TimeLine Graphs and Performance</u> | ||
| Line 158: | Line 156: | ||
* Yahoo Developer Network: Module 4: MapReduce Basics http://developer.yahoo.com/hadoop/tutorial/module4.html , a must-read! | * Yahoo Developer Network: Module 4: MapReduce Basics http://developer.yahoo.com/hadoop/tutorial/module4.html , a must-read! | ||
* Python and streaming, a [http://atbrox.com/2010/02/08/parallel-machine-learning-for-hadoopmapreduce-a-python-example/ tutorial] by [http://atbrox.com]. | * Python and streaming, a [http://atbrox.com/2010/02/08/parallel-machine-learning-for-hadoopmapreduce-a-python-example/ tutorial] by [http://atbrox.com]. | ||
| + | |||
| + | ===Installation Tutorials=== | ||
| + | |||
| + | * Jochen Leidner and Gary Berosik, [[http://arxiv4.library.cornell.edu/pdf/0911.5438v1| Building and Installing a Hadoop/MapReduce Cluster from Commodity Components]], [http://arxiv4.library.cornell.edu/pdf/0911.5438v1 library.cornell.edu], 2009. ([[Media:HadoopInstallationOnUbuntuLeidnerBerosik.pdf|cached copy]]) | ||
===Media Reports=== | ===Media Reports=== | ||
| Line 181: | Line 183: | ||
===Software/Web Links=== | ===Software/Web Links=== | ||
[[Image:HadoopCartoon.png | 100px | right]] | [[Image:HadoopCartoon.png | 100px | right]] | ||
| + | *[http://www.hadoopstudio.org/docs/tutorials/nb-tutorial-jobdev-streaming.html Karmasphere Studio] for Hadoop. An interesting IDE worth looking into... | ||
*[http://hadoop.apache.org/common/ Apache's Documentation on Hadoop Common] | *[http://hadoop.apache.org/common/ Apache's Documentation on Hadoop Common] | ||
**[http://hadoop.apache.org/common/docs/current/mapred_tutorial.html The Hadoop Tutorial] from Apache. A "Must-Do!" | **[http://hadoop.apache.org/common/docs/current/mapred_tutorial.html The Hadoop Tutorial] from Apache. A "Must-Do!" | ||
| Line 199: | Line 202: | ||
*[http://www.cloudera.com/blog/2009/04/20/configuring-eclipse-for-hadoop-development-a-screencast/ Configuring Eclipse for Hadoop] A video from Cloudera on setting up Hadoop... not easy to follow... | *[http://www.cloudera.com/blog/2009/04/20/configuring-eclipse-for-hadoop-development-a-screencast/ Configuring Eclipse for Hadoop] A video from Cloudera on setting up Hadoop... not easy to follow... | ||
* [https://trac.declarativity.net/browser/hadoop-0.19.1-bfs/src/examples/org/apache/hadoop/examples The source code for the examples] that come with the Hadoop 0.19.1 distribution. Includes WordCount, WordCountAggregate, WordCountHistogram, PiEstimator, Join, and Grep, among others. | * [https://trac.declarativity.net/browser/hadoop-0.19.1-bfs/src/examples/org/apache/hadoop/examples The source code for the examples] that come with the Hadoop 0.19.1 distribution. Includes WordCount, WordCountAggregate, WordCountHistogram, PiEstimator, Join, and Grep, among others. | ||
| − | + | * [http://github.com/datawrangling/spatialanalytics Spatial Analysis of Twitter Data with Hadoop, Pig, & Mechanical Turk], [http://github.com github.com], March 2010. | |
| + | |||
* <u>Generating Hadoop TimeLines</u> | * <u>Generating Hadoop TimeLines</u> | ||
** [http://people.apache.org/~omalley/tera-2009/job_history_summary.py Python script] from apache.org to generate the time line ([[CSC352 ApacheHadoopJobHistorySummary.py | Apache's script to generate Hadoop Timeline ]]). | ** [http://people.apache.org/~omalley/tera-2009/job_history_summary.py Python script] from apache.org to generate the time line ([[CSC352 ApacheHadoopJobHistorySummary.py | Apache's script to generate Hadoop Timeline ]]). | ||
| Line 232: | Line 236: | ||
<br /><br /><center><videoflash>qoBoEzOkeDQ</videoflash></center><br /><br /> | <br /><br /><center><videoflash>qoBoEzOkeDQ</videoflash></center><br /><br /> | ||
| − | * Monitoring a Cluster of Computers as a school of fish (U. Nebraska) | + | |
| + | * Monitoring a Cluster of Computers as a school of fish (U. Nebraska). | ||
| + | ::In this video, the researchers at U. of Nebraska decided to use fish swiming in a tank as a way of displaying what is going on with a cluster of many computers working on a large problem. All the computers are involved in a common computation. Each fish (as far as we can tell, given the lack of better information) represents a computer or a program running on a computer. As the user zooms in on a fish, a blue window pops up to give some vital information about that system's health. Fish change color and size to indicate a change in status. One could imaging that green fish represent computers not doing much work, which orange fish represent computers loaded with work. It is interesting to see how researchers would use a school of fish as a way to indicate what is going on in a cluster of computers, and relying on human beings's ability to recognize visual clues quickly to understand what is going on quickly and accurately. This is certainly better than trying to have the same human beings read tons of log files containing the date and time of many different events occurring in the cluster. | ||
<br /><br /><center><videoflash>LM1j_8sWSEk</videoflash></center><br /><br /> | <br /><br /><center><videoflash>LM1j_8sWSEk</videoflash></center><br /><br /> | ||
| Line 239: | Line 245: | ||
<br /> | <br /> | ||
| − | |||
[[CSC352_Notes | <font color="white">Notes</font>]] | [[CSC352_Notes | <font color="white">Notes</font>]] | ||
Latest revision as of 12:16, 31 July 2010
Contents
- 1 Resources: References & Bibliography for CSC352
Resources: References & Bibliography for CSC352
General Knowledge Papers
- Von Neumann J., First Draft of a Report on the EDVAC, Moore School of Electrical Engineering, University of Pennsylvania, June 30, 1945. (Especially interesting are the first 5 pages)
- Rob Weir's 4Z Method for reviewing papers.
Papers, Articles and University Courses on Parallel & Distributed Processing
- Parallelism in general
- Asanovic K. et al, The Landscape of Parallel Computing Research: A View from Berkeley, Dec. 2006. (cached copy)
- Performance Evaluation
- Lei Hu, and I. Gorton, Performance Evaluation for Parallel Systems: A Survey, University of NSW, Technical Report UNSW-CSE-TR-9707, October 1997 (cached copy)
- Video Tutorial: Optimizing Performance in Parallel Processing, Jan. 2010 (19 minutes)
- Amdahl's Law in the Multicore Era, Mark Hill and Michael Marty, IEEE Computer, July 2008, and accompanying dynamic graph. (cached copy)
- Xen
- Mauer, R., Xen Virtualization and Linux Clustering, Linux Journal January 12th, 2006
- Barham P., et al., Xen and the Art of Virtualization, University of Cambridge Computer Laboratory 15 JJ Thomson Avenue, Cambridge, UK, CB3 0FD
- AMD News
- Hardwidge, B., AMD plans supercomputer with 1,000 GPUs, Jan. 2009, bit-tech.net (or graphics goes to the clouds!)
- Halfacree G., AMD supercomputer tops TOP500 list, November 2009, bit-tech.net (or Intel gets a black eye!)
- Google University Code
- Lecture Notes by Paul Krzyzanowski for a course on Distributed Computing at Rutgers. Quite complete, and covering the basics of parallelism, RPC, synchronization, fault tolerance, security, and distributed file systems.
- The Fourth Paradigm: Data-Intensive Scientific Discovery, Microsoft Research, 2009. Table of Contents. A superb collection of essays on different topics (Low-res cached copy). The main chapters are:
- Part 1: Earth and Environment
- Part 2: Health and Wellbeing
- Part 3: Scientific Infrastructure
- Part 4: Scholarly Communication
- Final Thoughts
- Threading
- D. Tullsen, S. Eggers, and H. M. Levy, Simultaneous Multithreading: Maximizing On-Chip Parallelism, Proc. ISCA, Santa Margherita Ligure, Italy, 1997 (cached copy)
- Xgrid
- Hughes, B., Building Computational Grids with Apple's XGrid Middleware, ACM International Conference Proceeding Series, Vol. 167, Hobart, Tasmania, Australia, 2006. (cached copy)
- Tsouloupas G, and M. Dikaiakos, Characterization of Computational Grid Resources Using Low-Level Benchmarks, Second IEEE International Conference on e-Science and Grid Computing, Amsterdam, Netherlands, 2006 (cached copy)
- MapReduce
- Dean, J., and S. Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, Dec. 2004, (cached copy)
- Dan Gillick, Arlo Faria, John DeNero, MapReduce: Distributed Computing for Machine Learning, Berkeley U., 2006 (Cached Copy)
- Colby Ranger, Ramanan Raghuraman, Arun Penmetsa, Gary Bradski, Christos Kozyrakis, Evaluating MapReduce for Multi-core and Multiprocessor Systems, Stanford U., 2007 ( Cached Copy). (not for class presentation)
- Jeffrey Dean and Sanjay Ghemawat, MapReduce: A Flexible Data Processing Tool, CACM, Jan. 2010, Vol 53, No. 1 (Cached Copy)
- U Kang, Charalampos Tsourakakis, Ana Paula Appel, Christos Faloutsos, Jure Leskovec, HADI Fast Diameter Estimation and Mining in Massive Graphs with Hadoop, December 2008, Technical Report CMU-ML-08-117
Videos: Big Data and Analytics
| A |
video by Linkedin's Chief Scientist DJ Patil. As a mathematician specializing in dynamical systems and chaos theory, DJ began his career as a weather forecaster working for the Federal government. DJ shares his observations on how analytics has changed in recent years, especially as Big Data increasingly becomes common. |
| |
Roger Magoulas, from O'Reily Radar, discusses "big data" (10 minutes). |
| |
Jeff Veen: Designing for "Big Data", April 2009. |
Documentation on Python Threads

- The main Python reference
- Norman Matloff and Francis Hsu's Tutorial on Python Threads (University of California, Davis) (cached copy)
- Understanding Threading in Python, Krishna G Pai, Linux Gazette, Oct. 2004
- Thread Objects from Python.Org
- Multiprocessing with Python a presentation by Jesse Noller who wrote the PEP 371
- Video Presentation on the Python GIL (found by Diana)
Documentation on XGrid

- Introduction: What's an XGrid system?
- XGrid Overview from Apple
- Videos
- A Video presentation of the XGrid (click on movie reel icon to start).
- A YouTube short video showing the XGrid running the Mandelbrot demo.
- A very good overview of the XGrid from macdevcenter.com
- Programming Examples, Setup, and References relating to the XGrid system at Smith College.
- Tutorial #1: Monte Carlo
General References
- XGrid Admin and High Performance Computing document (PDF)
- Apple Xgrid
- Apple Xgrid FAQ
- MacDevCenter
- MacResearch
- Stanford Xgrid
- Utah Xgrid
Applications
- XGrid Programming Guide
- An Introduction to R
- POVray on the XGrid
- Stanford Xgrid: One of the largest XGrid systems around.
- Utah Xgrid: Lots of good stuff.
- Using the Mathematica Kernel.
Documentation on Cloud Computing, Map-Reduce, & Hadoop
"Failure is the defining difference between distributed and local programming"
Ken Arnold, CORBA Designer
Literature
- Apache's chapter on Hadoop Streaming, Apache.org.
- How to Benchmark a Hadoop Cluster, by Tom White, O'Reilly Answers, Oct. 2009.
- Hadoop, the definitive guide, Tom White, O'Reilly Media, June 2009, ISBN 0596521979. The Web site for the book is http://www.hadoopbook.com/ (with the data used as examples in the book)

- Dan Sullivan The Definitive Guide to Cloud Computing, IBM, 2010, in production (but can be downloaded in parts).
- Dean, J., and S. Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, Dec. 2004, (cached copy)
- Czajkowski G., Sorting 1 PB with MapReduce, Nov. 2008, (cached copy) (1 page only).
- Armbrust M, et al, Above the Clouds: A Berkeley View of Cloud Computing, Tech Rep. CB/EECS-2009-28, Feb. 2009 (cached copy)
- Olson C. et. al., Pig Latin: A Not-So-Foreign Language for Data Processing, SIGMOD’08, June 9–12, 2008, Vancouver, BC, Canada.
- Ghemawat S., H. Gobioff, and S.T. Leung, The Google File System, SOSP’03, October 19–22, 2003, Bolton Landing, New York, USA.
- The Fourth Paradigm: Data-Intensive Scientific Discovery, Microsoft Research, 2009. Table of Contents, (Low-res cached copy).
- Multicore Computing and Scientific Discovery, by Larus and Gannon
- Parallelism and the Cloud, by Gannon and Reed
- Visualization and Data-Intensive Science by Hansen, Johnson, Pascucci, and Silva.
- Talbot D., Security in the Ether, Technology Review, Jan/Feb 2010. (cached copy)
- HadoopWiki, Partitioning your job into Maps and Reduces, 2009.
- U Kang, Charalampos Tsourakakis, Ana Paula Appel, Christos Faloutsos, Jure Leskovec, HADI: Fast Diameter Estimation and Mining in Massive Graphs with Hadoop, December 2008, Technical Report CMU-ML-08-117
- Matthews, S., & Williams, T. MrsRF: an efficient MapReduce algorithm for analyzing large collections of evolutionary trees BMC Bioinformatics, 11, 2010 (Suppl 1) (authors show that speedups of close to 18 on 32 cores can be reached for treating 20,000 trees of 150 taxa each and 33,306 trees of 567 taxa each.)
- Chris K Wensel, Hadoop Is About Scalability, Not Performance, www.manamplified.org, November 12, 2008.
- Pavlo, Paulson, Rasin, Abadi, DeWitt, Madden, and Stonebraker, A Comparison of Approaches to Large Scale Data-Analysis, SIGMOD-09, June 2009.

- TimeLine Graphs and Performance
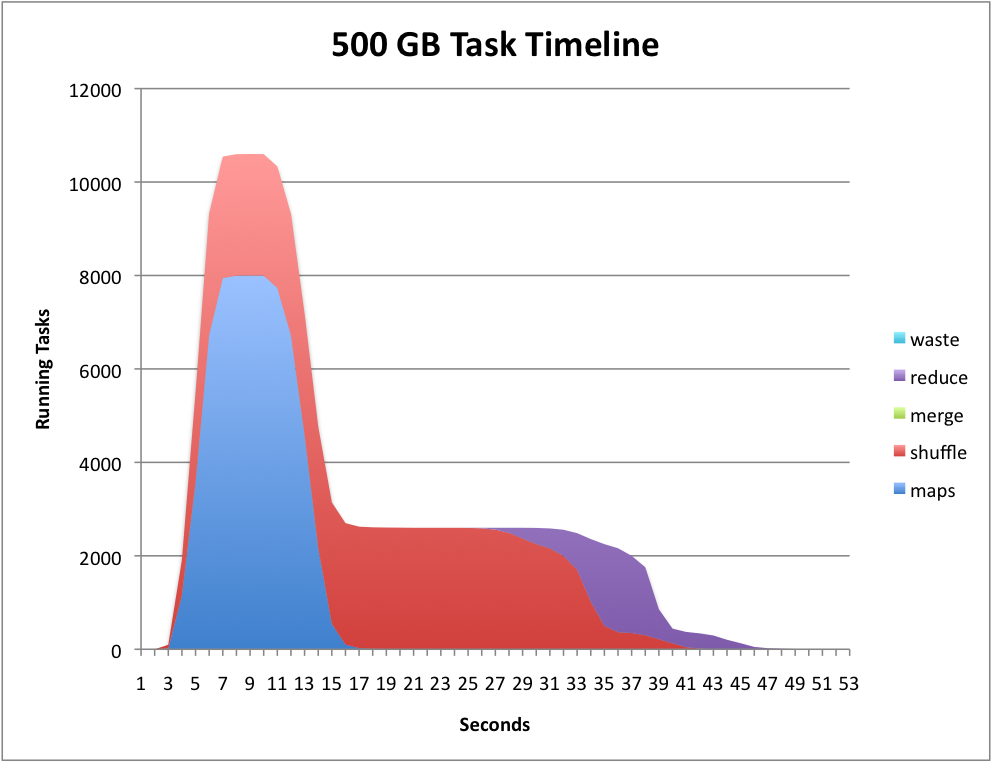
- Owen O'Malley and Arun Murthy, Hadoop Sorts a Petabyte in 16.25 Hours and a Terabyte in 62 Seconds, http://developer.yahoo.net, May 2009.
- Joseph Gebis, Understanding Hadoop Task Timelines, http://blogs.sun.com, June 2009. (A good description of the Task Timelines used to quantify hadoop performance)
- Joseph Gebis, Hadoop Resource Utilization Monitoring -- scripts, http://blogs.sun.com, June 2009.
- Joseph Gebis, Hadoop resource utilization and performance analysis, http://blogs.sun.com, June 2009.
- Elias Torres, Hadoop TimeLines, http://hadoop-timelines.appspot.com, c. 2009.

Collections of Hadoop Papers and/or Algorithms
Presentations
- Milind Bhandarkar, Data-Intensive Computing with Hadoop, Yahoo, Inc., Sept. 2008.
Tutorials
- Tom White, Running Hadoop MapReduce on Amazon EC2 and S3, Amazon Web Services Articles and Tutorials, 2007.
- Robert Sosinski, Starting Amazon EC2 with Mac OS X, www.robertsosinski.com, 2008.
- Introduction to Java for AWS developers, Amazon Web Services, 2007.
- Aaron Jacob (Evri.com)Using Cloudera's Hadoop AMIs to process EBS datasets on EC2, www.facebook.com, 2009. ( cached copy)
- Yahoo Developer Network: Module 4: MapReduce Basics http://developer.yahoo.com/hadoop/tutorial/module4.html , a must-read!
- Python and streaming, a tutorial by [1].
Installation Tutorials
- Jochen Leidner and Gary Berosik, [Building and Installing a Hadoop/MapReduce Cluster from Commodity Components], library.cornell.edu, 2009. (cached copy)
Media Reports
- Markoff, J., A Deluge of Data Shapes a New Era in Computing, New York Times, 12/15/09
News Feed
- cloud-computing.alltop.com: aggregated news about the cloud
Class Material on the Web
- Google's series of 4 lectures on map-reduce, distributed file-system, and clustering algorithms.
- University of Washington: Problem Solving on Large Scale Clusters
- Brandeis University: Distributed Systems Course
- Google: Introduction to Parallel Programming and MapReduce
- U. C. Berkeley: Intro to Parallel Programming and Threading
- California PolyTech: A lab on the NetFlix data set
- New Mexico Tech: syllabus (pdf)
- U. Maryland: Syllabus, and Jimmy Lin's Cloud 9 page.
Software/Web Links

- Karmasphere Studio for Hadoop. An interesting IDE worth looking into...
- Apache's Documentation on Hadoop Common
- The Hadoop Tutorial from Apache. A "Must-Do!"
- Hadoop Streaming, i.e. using Hadoop with Python, for example.
- A Yahoo Tutorial on Hadoop. Another "Must-Do!"
- An Hadoop-On-Eclipse tutorial. For Windows platform but works for Macs as well. Best way to setup Eclipse! You will need Eclipse 3.3.2 and Hadoop 0.19.1.
- The Hadoop-Book Web site.
- The Hadoop Wiki, the authoritative source on working with Hadoop. Many examples in Java and Python
- Hadoop at Google: A preconfigured single node instance available at Google.
- Writing the WordCount in Python
- Guide for setting up IBM's Eclipse Tools for Hadoop (go to bottom of page)
- The IBM MapReduce Tools for Eclipse Plug-in is a robust plug-in that brings Hadoop support to the Eclipse platform. Features include server configuration, support for launching MapReduce jobs and browsing the distributed file system. This setup assumes that you are running Eclipse (version 3.3 or above) on your computer.
- Guide from Cornell for setting up Hadoop on a Mac.
- Configuring Eclipse for Hadoop A video from Cloudera on setting up Hadoop... not easy to follow...
- The source code for the examples that come with the Hadoop 0.19.1 distribution. Includes WordCount, WordCountAggregate, WordCountHistogram, PiEstimator, Join, and Grep, among others.
- Spatial Analysis of Twitter Data with Hadoop, Pig, & Mechanical Turk, github.com, March 2010.
- Generating Hadoop TimeLines
- Python script from apache.org to generate the time line ( Apache's script to generate Hadoop Timeline ).
Videos
- Google's series of 4 lectures on map-reduce, distributed file-system, and clustering algorithms.
- Berkeley lecture on Map-Reduce (CS 61A Lecture 34)
- A video of Tom White, author of O'Reilly's Hadoop guide, on BlipTV. White outlines the suite of projects centered around Hadoop ( an open source Map / Reduce project)
- Cloudera's collection of videos.
- CNBC's report: Inside the Mind of Google. "The best way to watch “Inside the Mind of Google,” Maria Bartiromo’s report on the Internet giant Thursday on CNBC, is to not watch the first quarter of it. (from Neil enzlinger's 12/02/09 NYT review)
- Short video by consultant at http://www.stratoslearning.com (5 min) . Outlines a course on Cloud Computing.
- Part I: cloud fondamentals
- Part II: technology and barriers
- Part III: security
- Part IV: what options? players?
- Part V: Application, hands on
- Users Amazon as test platform.
Visualizations
- Visualizations of Hadoop Data Transfers, from the U. of Nebraska (more videos)
- Monitoring a Cluster of Computers as a school of fish (U. Nebraska).
- In this video, the researchers at U. of Nebraska decided to use fish swiming in a tank as a way of displaying what is going on with a cluster of many computers working on a large problem. All the computers are involved in a common computation. Each fish (as far as we can tell, given the lack of better information) represents a computer or a program running on a computer. As the user zooms in on a fish, a blue window pops up to give some vital information about that system's health. Fish change color and size to indicate a change in status. One could imaging that green fish represent computers not doing much work, which orange fish represent computers loaded with work. It is interesting to see how researchers would use a school of fish as a way to indicate what is going on in a cluster of computers, and relying on human beings's ability to recognize visual clues quickly to understand what is going on quickly and accurately. This is certainly better than trying to have the same human beings read tons of log files containing the date and time of many different events occurring in the cluster.
- The evolution of Hadoop (Code-Swarm)